Es ist ungewöhnlich, dass kein Intercept passt und im Allgemeinen nicht ratsam ist - man sollte dies nur tun, wenn man weiß, dass es 0 ist, aber ich denke das (und die Tatsache, dass man die $ R ^ 2 $ für Passungen mit und ohne nicht vergleichen kann Intercept) ist bereits wirklich abgedeckt (wenn im Fall des 0-Intercept möglicherweise etwas überbewertet); Ich möchte mich auf Ihr Hauptproblem konzentrieren, nämlich, dass die angepasste Funktion positiv sein muss, obwohl ich in einem Teil meiner Antwort auf das 0-Intercept-Problem zurückkomme.
Der beste Weg, um ein Immer zu erhalten Positive Passform bedeutet, etwas zu passen, das immer positiv sein wird. Dies hängt zum Teil davon ab, welche Funktionen Sie anpassen müssen.
Wenn Ihr lineares Modell weitgehend zweckmäßig war (anstatt aus einer bekannten funktionalen Beziehung zu stammen, die beispielsweise aus einem physischen Modell stammen könnte), dann Sie könnte stattdessen mit der Protokollzeit arbeiten; Das angepasste Modell ist dann garantiert positiv in $ t $. Alternativ können Sie eher mit Geschwindigkeit als mit Zeit arbeiten. Bei linearen Anpassungen kann es jedoch zu Problemen mit kleinen Geschwindigkeiten (langen Zeiten) kommen.
Wenn Sie wissen, dass Ihre Antwort in den Prädiktoren linear ist, Sie können versuchen, eine eingeschränkte Regression anzupassen, aber bei mehrfacher Regression hängt die genaue Form, die Sie benötigen, von Ihren speziellen x ab (es gibt keine lineare Einschränkung, die für alle $ x $ funktioniert) Bit ad-hoc.
Sie können sich auch GLMs ansehen, mit denen Modelle angepasst werden können, die nicht negative Anpassungswerte aufweisen und (falls erforderlich) sogar $ E (Y) = X \ beta $ haben können .
Beispielsweise kann ein Gamma-GLM mit Identitätsverknüpfung versehen werden. Sie sollten keinen negativen Anpassungswert für eines Ihrer x erhalten (aber in einigen Fällen können Konvergenzprobleme auftreten, wenn Sie den Identitätslink erzwingen, wo er wirklich nicht passt).
Hier ist ein Beispiel: Der Datensatz cars in R, der Geschwindigkeit und Bremswege (die Antwort) aufzeichnet.
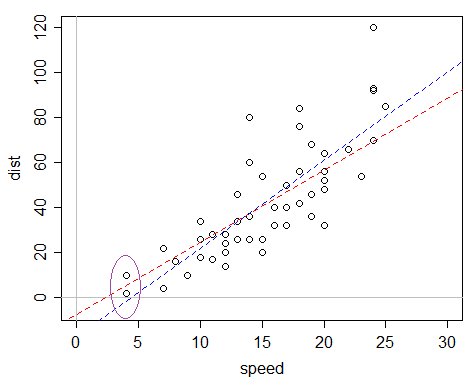
Man könnte sagen "oh, aber der Abstand für Geschwindigkeit 0 ist garantiert 0, also sollten wir den Achsenabschnitt weglassen", aber das Problem mit dieser Argumentation ist, dass das Modell auf verschiedene Weise falsch spezifiziert ist und dieses Argument nur gut funktioniert genug, wenn das Modell nicht falsch spezifiziert ist - ein lineares Modell mit einem Achsenabschnitt von 0 passt in diesem Fall überhaupt nicht gut, während eines mit einem Achsenabschnitt tatsächlich eine halbwegs anständige Annäherung ist, obwohl es nicht wirklich "korrekt" ist.
Das Problem ist, wenn Sie eine gewöhnliche lineare Regression anpassen, ist der angepasste Achsenabschnitt ziemlich negativ, was dazu führt, dass die angepassten Werte negativ sind.
Die blaue Linie entspricht der OLS-Anpassung. Der angepasste Wert für die kleinsten x-Werte im Datensatz ist negativ. Die rote Linie ist das Gamma-GLM mit Identitätsverknüpfung - während es einen negativen Achsenabschnitt hat, hat es nur positiv angepasste Werte. Dieses Modell weist eine Varianz auf, die proportional zum Mittelwert ist. Wenn Sie also feststellen, dass Ihre Daten mit zunehmender erwarteter Zeit weiter verbreitet sind, ist es möglicherweise besonders geeignet.
Dies ist also ein möglicher alternativer Ansatz, der einen Versuch wert sein kann. Es ist fast so einfach wie das Anpassen einer Regression in R.
Wenn Sie den Identitätslink nicht benötigen, können Sie andere Linkfunktionen wie den Log-Link und den inversen Link in Betracht ziehen, die sich auf die Transformationen beziehen bereits besprochen, aber ohne die Notwendigkeit einer tatsächlichen Transformation.
Da die Leute normalerweise danach fragen, ist hier der Code für meine Handlung:
Handlung (Geschwindigkeit, Daten = Autos, xlim = c (0, 30), ylim = c (-5.120)) abline (h = 0, v = 0, col = 8) abline (glm (Geschwindigkeit, Daten = Autos, Familie = Gamma (Link = Identität)), col = 2 , lty = 2) abline (lm (dist ~ speed, data = cars), col = 4, lty = 2)
(Die Ellipse wurde anschließend von Hand hinzugefügt, obwohl dies einfach genug ist auch in R zu tun)