Dies ist nicht der Fall.
Damit $ \ log (X) $ normal ist, muss $ X $ lognormal sein.
(Beachten Sie: wenn $ Z = \ log ( X) $ ist normal, dann ist $ X = \ exp (Z) $ ... und wenn Sie eine normale Zufallsvariable potenzieren, wird das, was Sie erhalten, als logarithmische Zufallsvariable bezeichnet.)
Allgemeiner genommen Protokolle "ziehen" extremere Werte rechts (hohe Werte) relativ zum Median ein, während Werte ganz links (niedrige Werte) dazu neigen, nach hinten gestreckt zu werden. Wenn es also vor dem Erstellen von Protokollen symmetrisch ist, bleibt es danach relativ schief. Dies ist eine einfache Folge der Form der Funktion $ \ log (x) $:
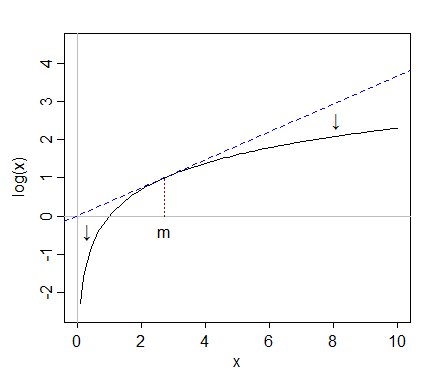
(die Linie tangiert die Kurve. Im Allgemeinen nicht Wenn Sie sich nicht unbedingt dem Ursprung nähern, ist dies in diesem Fall nur ein Artefakt des bestimmten Werts von $ m $.
Werte, die sehr nahe am Median liegen (angezeigt durch ein $ m $ im Diagramm), werden auftreten eine annähernd lineare Neuskalierung (die gestrichelte blaue Linie). Werte weit über $ m $ werden relativ zu der von den Mittelwerten erlebten Neuskalierung in Richtung $ m $ zurückgezogen, während Werte weit unter $ m $ im Verhältnis zu dieser linearen Neuskalierung weiter von $ m $ entfernt werden. P. >
Infolgedessen sind Werte in gleichem Abstand, $ d $ über und unter $ m $ vor der Transformation, danach nicht mehr gleich weit davon entfernt - der oben transformierte Wert liegt näher an $ \ log (m) $ als der transformierte Wert darunter wird sein. Dies würde für jeden Wert von $ d $ passieren.
Symmetrisch $ X $ impliziert also asymmetrisch $ \ log (X) $.
Sprechen wir jetzt nicht über Normalität, sondern über ungefähre Normalität. (Nehmen wir der Einfachheit halber an, dass die Verteilung so ist, dass die Werte im Wesentlichen immer positiv sind - dh wenn die ursprünglichen Werte normal waren, ist die Wahrscheinlichkeit eines negativen Werts extrem gering.)
Es gibt einen Situation, in der annähernd normale Werte nach der Transformation immer noch annähernd normal sind.
In diesem Fall ist die Standardabweichung im Vergleich zum Mittelwert (niedriger Variationskoeffizient) sehr klein.
Wenn Sie sich das obige Diagramm ansehen, betrachten Sie Werte auf der x-Achse in einem sehr schmalen Band um $ m $. Der Einzieh- / Ausdehnungseffekt ist minimal (die schwarze Kurve kann nicht weit von der blauen Tangentenlinie entfernt werden), sodass die Form immer noch normal aussieht.
Hier ein Beispiel: Das obere Diagramm ist ein Satz von ungefähr normalen Daten (das QQ-Diagramm zeigt eine ziemlich gerade Linie), und sein Protokoll ist ebenfalls ungefähr normal (das QQ-Diagramm zeigt immer noch eine ziemlich gerade Linie). Das liegt daran, dass der Variationskoeffizient der ursprünglichen Werte ziemlich klein war (irgendwo um 0,2, glaube ich) - die nichtlineare Transformation war im engen Wertebereich um die Mitte immer noch nahezu linear .
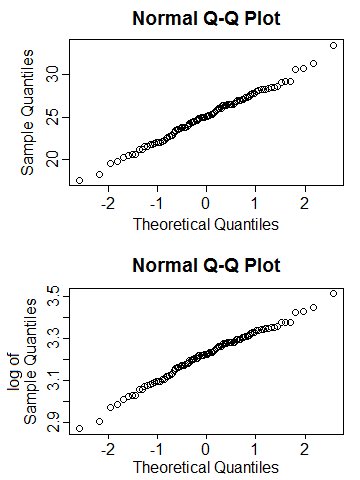
In dieser Situation ist die Delta-Methode in der Tat nützlich, um ungefähre Werte für den Mittelwert und die Varianz der logarithmischen Werte anzugeben, obwohl dies nicht die Verteilung der Werte wäre Protokoll einer genau normalen Zufallsvariablen.