Dieser Teil des Wikipedia-Artikels lässt zu wünschen übrig. Lassen Sie uns zwei Aspekte trennen:
Die Notwendigkeit nichtlinearer Aktivierungsfunktionen
Es ist offensichtlich, dass ein Feedforward-neuronales Netzwerk mit linearen Aktivierungsfunktionen und $ n $ span> -Schichten jeweils $ m $ hat span> versteckte Einheiten (der Kürze halber lineares neuronales Netzwerk) entspricht einem linearen neuronalen Netzwerk ohne versteckte Schichten. Beweis:
$$ y = h (\ mathbf {x}) = \ mathbf {b} _n + W_n (\ mathbf {b} _ {n-1} + W_ {n -1} (\ dots (\ mathbf {b} _1 + W_1 \ mathbf {x}) \ dots)) = \ mathbf {b} _n + W_n \ mathbf {b} _ {n-1} + W_nW_ {n- 1} \ mathbf {b} _ {n-2} + \ dots + W_nW_ {n-1} \ dots W_1 \ mathbf {x} = \ mathbf {b} '+ W' \ mathbf {x} $$ span>
Somit ist klar, dass das Hinzufügen von Schichten ("tief gehen") die Approximationsleistung eines linearen neuronalen Netzwerks überhaupt nicht erhöht , anders als bei einem nichtlinearen neuronalen Netzwerk.
Außerdem sind nichtlineare Aktivierungsfunktionen erforderlich, damit der universelle Approximationssatz für neuronale Netze gültig ist. Dieser Satz besagt, dass unter bestimmten Bedingungen für jede stetige Funktion $ f: [0,1] ^ d \ bis \ mathbb {R} $ span> und jede $ \ epsilon>0 $ span> gibt es ein neuronales Netzwerk mit einer verborgenen Schicht und einer ausreichend großen Anzahl versteckter Einheiten $ m $ span>, die approximiert $ f $ span> auf $ [0,1] ^ d $ span> gleichmäßig auf $ \ epsilon $ span>. Eine der Bedingungen für die Gültigkeit des universellen Approximationssatzes ist, dass das neuronale Netzwerk eine Zusammensetzung von nichtlinearen Aktivierungsfunktionen ist: Wenn nur lineare Funktionen verwendet werden, ist der Satz nicht mehr gültig. Daher wissen wir, dass es über Hyperwürfel einige kontinuierliche Funktionen gibt, die wir mit linearen neuronalen Netzen einfach nicht genau approximieren können.
Dank des Tensorflow-Spielplatzes können Sie die Grenzen linearer neuronaler Netze in der Praxis erkennen. Ich habe ein lineares neuronales Netzwerk mit 4 versteckten Schichten zur Klassifizierung aufgebaut. Wie Sie sehen können, kann das lineare neuronale Netzwerk unabhängig von der Anzahl der verwendeten Schichten nur lineare Trenngrenzen finden, da es einem linearen neuronalen Netzwerk ohne versteckte Schichten, d. H. Einem linearen Klassifizierer, entspricht.
Die Notwendigkeit von ReLU
Die Aktivierungsfunktion $ h (s) = \ max (0, cs) $ span> wird nicht verwendet, weil "sie die Nichtlinearität der Entscheidungsfunktion erhöht": was auch immer Das kann bedeuten, dass ReLU nicht nichtlinearer ist als $ \ tanh $ span>, Sigmoid usw. Der eigentliche Grund, warum es verwendet wird, ist, dass beim Stapeln von immer mehr Ebenen in a CNN wurde empirisch beobachtet, dass ein CNN mit ReLU viel einfacher und schneller zu trainieren ist als ein CNN mit $ \ tanh $ span> (die Situation mit einem Sigmoid ist noch schlimmer ). Wieso ist es so? Derzeit gibt es zwei Theorien:
- $ \ tanh (s) $ span> hat das Problem verschwindender Gradient . Da die unabhängige Variable $ s $ span> an $ \ pm \ infty $ span> geht, die Ableitung von $ \ tanh (s) $ span> geht auf 0:
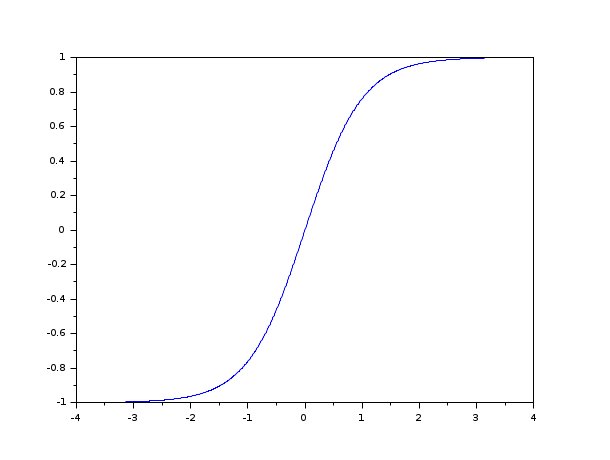
Dies bedeutet, dass die Farbverläufe kleiner werden, wenn mehr Ebenen gestapelt werden
und kleiner. Seit dem Schritt im Gewichtsraum der Backpropagation
Der Algorithmus ist proportional zur Größe des Gradienten und verschwindet
Gradienten bedeuten, dass das neuronale Netzwerk nicht mehr trainiert werden kann.
Dies äußert sich in exponentiell zunehmenden Trainingszeiten
mit der Zunahme der Anzahl der Schichten. Im Gegenteil, die
Die Ableitung von ReLU ist konstant (gleich $ c $ span>), wenn $ s>0 $ span>, egal wie
viele Ebenen stapeln wir (es ist auch gleich 0, wenn $ s<0 $ span> führt, was dazu führt
das Problem tote Neuronen , aber dies ist ein weiteres Problem).
- Es gibt Theoreme, die garantieren, dass lokale Minima unter bestimmten Bedingungen globale Minima sind (siehe hier).Einige der Annahmen dieser Theoreme gelten nicht, wenn die Aktivierungsfunktion ein $ \ tanh $ span> oder ein Sigmoid ist, aber sie gelten, wenn die Aktivierungsfunktion eine ReLU ist.
