Vergessen Sie nicht, dass Buchseiten auch unterschiedlich viele Wörter enthalten. Die Variation hängt von akkumulierten kleinen Unterschieden ab, die sich auf Wortlänge, Seitenbreite, Absatzlänge, Anzahl der Dialoge usw. beziehen. Für ein Buch mit einheitlich aussehenden Seiten können wir daher erwarten, dass diese Variation normal ist, mit Ausnahme von für die Enden und Anfänge von Kapiteln. Die Endseiten haben ungefähr eine gleichmäßige Verteilung der Wortlängen. Die Anfangsseiten haben ungefähr eine Normalverteilung mit einem kleineren Mittelwert als die typische (vollständige) Seite, abhängig vom Seitendesign.
Dies ergibt eine komplexe Verteilung, die jedoch relativ einfach zu simulieren ist. Die Parameter sollten
-
umfassen. Die mittlere Anzahl von Wörtern pro (vollständiger) Seite, $ w $ span>. Sie können dies leicht für tatsächliche Bücher messen, die Sie simulieren möchten.
-
Die Standardabweichung in Wörtern pro (vollständiger) Seite, $ s $ span>. Auch dies ist leicht zu messen.
-
Die mittlere Anzahl von Wörtern pro Startseite, $ u $ span>, ebenfalls leicht zu messen.
-
Die Protokollvariation in den Lesezeiten, $ \ sigma $ span>. Verwenden Sie zu Beginn einen Wert von etwa 12%, basierend auf Nielsens Studie. Betrachten Sie andere Studien nach anderen realistischen Werten.
-
Die Lesegeschwindigkeit des Benutzers, $ v $ span>, als Wörter pro Minute, sagen wir. Je nach Lesertyp werden häufig Werte zwischen 200 und 250 wpm verwendet.
-
Die durchschnittliche Anzahl der Seiten pro Kapitel, $ n $ span>, auch leicht zu messen.
-
Die mittlere Umblätternde Zeit, $ t $ span>. Sie könnten Ihre eigene kleine Studie über Leser machen, vielleicht indem Sie eine Stunde mit einer Stoppuhr in einer Bibliothek verbringen :-). Seien Sie bei dieser Zahl nicht zu pingelig - sie hängt von der Buchgröße, dem Seitenmaterial und dem Leser ab -, aber sie könnte genügend Zeit einbringen, um für die Simulation von Interesse zu sein.
Die Simulation sollte ein ganzes Kapitel umfassen, das als Sequenz aus einer Startseite, $ n-2 $ span> normalen Seiten und einer Endseite simuliert wird . Simulieren Sie die Anzahl der Wörter $ m $ span> als
$$ m = (n-2) ) w + u + zw + r $$ span>
wobei $ z $ span> einen einheitlichen $ (0,1) $ span> -Verteilung und $ r $ span> haben eine Normalverteilung mit dem Mittelwert $ 0 $ span> und Standardabweichung $ s \ sqrt {n} $ span>.
Zeichnen Sie einen Wert $ x $ span> aus einer Normalverteilung mit dem Mittelwert $ 0 $ span> und der Standardabweichung $ \ sigma $ span>. Multiplizieren Sie $ m $ span> mit $ w \ exp (x) / v $ span>, um die Lesezeit zu simulieren. Fügen Sie $ nt $ span> Minuten für die Seitenumbrüche hinzu.
Dieser Prozess erfasst die wichtigsten Einflüsse auf die Lesezeit für ein Buch mit homogenem Text und einheitlichem Text Leseschwierigkeiten und keine Abbildungen. Bei komplexeren Büchern, z. B. Lesesammlungen, Mathematik oder Naturwissenschaften, Büchern mit vielen Dialogen, illustrierten Büchern usw., muss das Modell möglicherweise komplexer sein, um realistisch zu sein.
Edit
Es stellt sich heraus, dass wir den Vorschlag von @Jason möglicherweise rechtfertigen und konkretisieren können, da diese komplexe, aber realistische Simulation durch eine -Version sehr gut angenähert werden kann einer Gammaverteilung in den meisten Fällen. Wir müssen das Gamma neu skalieren und verschieben, zusätzlich zur Auswahl seines Formparameters.
Hier ist ein (typisches) Beispiel, das auf $ 100.000 $ span> -Iterationen basiert mit $ w = 300 $ span> Wörter pro Seite, $ s = 15 $ span> Wörter (SD pro Seite), $ u = 100 $ span> Wörter pro Startseite, $ \ sigma = 0,12 $ span>, $ v = 250 $ span> Wörter pro Minute, $ n = 8 $ span> Seiten pro Kapitel und $ t = 0,04 $ span> Minuten pro Seitenumbruch.
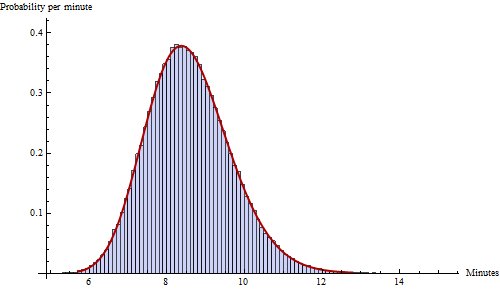
Das Histogramm gibt die Verteilung der Ergebnisse an, während die durchgezogene rote Kurve das PDF für a ist Gammaverteilung mit Formparameter $ 27.416 $ span>, Skalierungsparameter $ 0.2043 $ span>, versetzt um $ 2.98 $ span> Minuten.
Diese Annäherung bricht nur für extrem kurze Kapitellängen zusammen, ist aber auch dann noch anständig, wenn $ n = 3 $ span>:
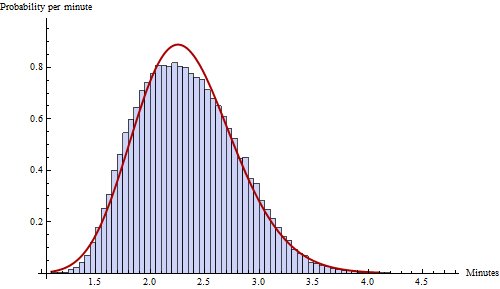
Der potenzielle Vorteil dieser Beobachtung besteht darin, dass Sie vermeiden können, viele der Parameter zu schätzen, die zum Modellieren des Lesens eines einfachen, homogenen Buches erforderlich sind, wenn Sie bereit sind, drei unabhängige Parameter des zu spezifizieren Verteilung, wie Mittelwert, Standardabweichung und Schiefe. Wenn Sie beispielsweise tatsächliche Daten zu den Kapitellesezeiten haben, können Sie die ersten drei Beispielmomente verwenden, um eine Gammaverteilung mit drei Parametern an die Daten anzupassen, und dann die Simulation über Zeichnungen aus diesem Gamma durchführen.
Außerdem Wenn Sie davon ausgehen, dass die Zeiten zum Lesen der Buchkapitel unabhängig sind, können Sie diese Gammas (eine pro Kapitel) leicht hinzufügen, um eine Verteilung für die Zeitdauer zum Lesen des gesamten Buches zu erhalten (da der Formparameter für die Summe von Gamma Verteilungen mit einem gemeinsamen Skalierungsfaktor sind die Summe ihrer Formparameter. Selbst mit minimalen Daten (wie hier verwendet) können Sie einige Simulationen für ein einzelnes Kapitel ausführen, ein Gamma an diese Simulationsergebnisse anpassen und die gesamten Lesezeiten des Buches ableiten (anstatt zu simulieren).
In diesem Fall sollten beispielsweise die Lesezeiten für ein Buch mit Kapiteln von $ 16 $ span> einer Gamma-Verteilung mit dem Formparameter $ 16 \ mal 27,4164 $ span>, Skalierungsparameter $ 0,2043 $ span>, versetzt um $ 16 \ mal 2,98 $ span> Minuten. Bei vielen Büchern (mit vielen Kapiteln) ist die resultierende Verteilung für alle praktischen Zwecke normal. Die Wahrscheinlichkeit, die durch diese Verteilung negativen Werten zugewiesen wird, wäre astronomisch so gering, dass es keine Rolle spielt.
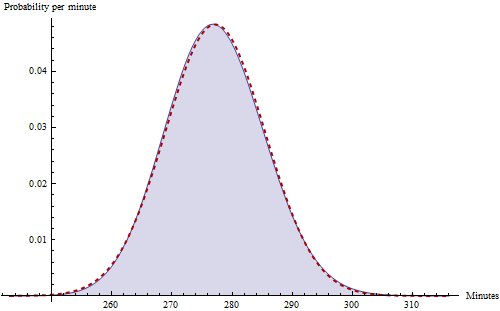
Die blaue Kurve zeigt die Verteilung der Buchlesezeiten. Die darüber gestrichelte gestrichelte rote Kurve ist eine normale Näherung. Keine der beiden Verteilungen weist Zeiten von weniger als 240 Minuten eine nennenswerte Wahrscheinlichkeit zu.