Normalerweise würden Sie den beobachteten Wert nicht als "geschätzten Wert" bezeichnen.
Trotzdem ist der beobachtete Wert technisch gesehen eine Schätzung des Mittelwerts bei seinem bestimmten $ x $, und wenn er als Schätzung behandelt wird, wird uns dies tatsächlich mitgeteilt Sinn, in dem OLS den Mittelwert dort besser abschätzen kann.
Im Allgemeinen wird die Regression in der Situation verwendet, in der Sie, wenn Sie eine andere Stichprobe mit denselben $ x $ nehmen würden, nicht dieselben Werte für die $ y $ erhalten würden. Bei der gewöhnlichen Regression behandeln wir $ x_i $ als feste / bekannte Größen und die Antworten, $ Y_i $ als Zufallsvariablen (wobei beobachtete Werte mit $ y_i $ bezeichnet werden).
Verwenden Sie eine häufigere Notation. wir schreiben
$$ Y_i = \ alpha + \ beta x_i + \ varepsilon_i $$
Der Rauschbegriff $ \ varepsilon_i $ ist wichtig, weil die Beobachtungen nicht richtig liegen auf der Bevölkerungslinie (wenn dies der Fall wäre, wäre keine Regression erforderlich; zwei beliebige Punkte würden Ihnen die Bevölkerungslinie geben); Das Modell für $ Y $ muss die Werte berücksichtigen, die es annimmt, und in diesem Fall berücksichtigt die Verteilung des Zufallsfehlers die Abweichungen von der ('wahren') Linie.
Die Schätzung des Mittelwerts am Punkt $ x_i $ für gewöhnliche lineare Regression hat Varianz
$$ \ Big (\ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} \ Big) \, \ sigma ^ 2 $$
, während die auf dem beobachteten Wert basierende Schätzung die Varianz $ \ sigma ^ 2 $ aufweist.
Es ist möglich zu zeigen, dass für $ n $ mindestens 3 $ \, \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} $ ist nicht mehr als 1 (aber es kann - und in der Praxis normalerweise - viel kleiner sein). [Wenn Sie die Anpassung auf $ x_i $ durch $ y_i $ schätzen, bleibt Ihnen auch die Frage, wie $ \ sigma $ geschätzt werden soll.]
Aber anstatt die formelle Demonstration fortzusetzen, überlegen Sie Ein Beispiel, von dem ich hoffe, dass es motivierender ist.
Lassen Sie $ v_f = \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum ( x_i- \ bar {x}) ^ 2} $, der Faktor, mit dem die Beobachtungsvarianz multipliziert wird, um die Varianz der Anpassung bei $ x_i $ zu erhalten.
Lassen Sie uns jedoch eher auf der Skala des relativen Standardfehlers als der relativen Varianz arbeiten (dh schauen wir uns die Quadratwurzel dieser Größe an). Konfidenzintervalle für den Mittelwert bei einem bestimmten $ x_i $ sind ein Vielfaches von $ \ sqrt {v_f} $.
Also zum Beispiel. Nehmen wir die Autos -Daten in R; Dies sind 50 Beobachtungen, die in den 1920er Jahren über die Geschwindigkeit von Autos und die zum Anhalten zurückgelegten Entfernungen gesammelt wurden:
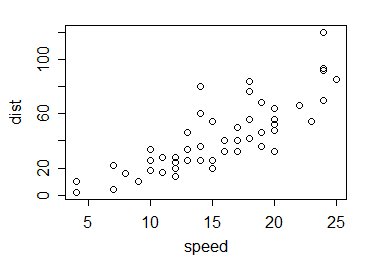
Wie verhalten sich die Werte von $ \ sqrt {v_f} $? mit 1 vergleichen? So:
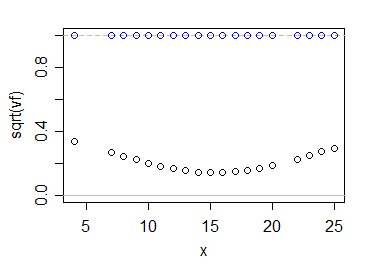
Die blauen Kreise zeigen die Vielfachen von $ \ sigma $ für Ihre Schätzung, während die schwarzen sie für die übliche Schätzung der kleinsten Quadrate anzeigen. Wie Sie sehen, macht die Verwendung der Informationen aus allen Daten unsere Unsicherheit darüber, wo der Populationsmittelwert liegt, wesentlich geringer - zumindest in diesem Fall und natürlich angesichts der Richtigkeit des linearen Modells.
Infolgedessen Wenn wir ein 95% -Konfidenzintervall für den Mittelwert für jeden Wert $ x $ (einschließlich an anderen Stellen als einer Beobachtung) zeichnen (sagen wir), sind die Grenzen des Intervalls an den verschiedenen $ x $ im Vergleich zu dem normalerweise klein Variation der Daten:
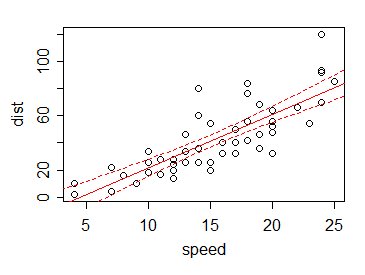
Dies ist der Vorteil des Ausleihens von Informationen aus anderen als den vorliegenden Datenwerten.
In der Tat können wir die Informationen aus anderen Werten - über die lineare Beziehung - verwenden, um gute Schätzungen des Werts an Stellen zu erhalten, an denen wir nicht einmal Daten haben. Bedenken Sie, dass es in unserem Beispiel keine Daten bei x = 5, 6 oder 21 gibt. Mit dem vorgeschlagenen Schätzer haben wir dort keine Informationen - aber mit der Regressionslinie können wir nicht nur den Mittelwert an diesen Punkten (und bei 5,5 und 12,8 und) schätzen usw.) können wir ein Intervall dafür angeben - allerdings auch eines, das von der Eignung der Linearitätsannahmen (und der konstanten Varianz der $ Y $ s und der Unabhängigkeit) abhängt.