Konfidenzintervalle ändern sich nicht, wenn Sie die Parameter transformieren (mit einer monotonen Transformation)
Konfidenzintervalle basieren auf Wahrscheinlichkeiten, die von den Parametern abhängig sind, und werden nicht transformiert, wenn Sie die Parameter transformieren. Im Gegensatz zu (Bayes'schen) Wahrscheinlichkeiten der Parameter (auf denen glaubwürdige Intervalle basieren). Siehe zum Beispiel in dieser Frage: Wenn ein glaubwürdiges Intervall einen flachen Prior hat, entspricht ein 95% -Konfidenzintervall einem glaubwürdigen 95% -Intervall? Ein Konfidenzintervall ist nicht gerecht wie ein glaubwürdiges Intervall mit einem flachen Prior. Für ein Konfidenzintervall haben wir :
- TDie Grenzen der Wahrscheinlichkeiten (Glaubwürdigkeitsintervalle) unterscheiden sich, wenn Sie die Variable transformieren (für Wahrscheinlichkeitsfunktionen ist dies nicht der Fall). . ZB für einen Parameter $ a $ span> und eine monotone Transformation $ f (a) $ span> (zB Logarithmus) Sie Holen Sie sich die äquivalenten Wahrscheinlichkeitsintervalle
$$ \ begin {array} {ccccc}
a _ {\ min} &<& a &<& a _ {\ max} \\
f (a _ {\ min}) &<& f (a) &<& f (a _ {\ max})
\ end {array} $$ span>
Warum ist das so?
Siehe in dieser Frage Können wir eine Nullhypothese mit Konfidenzintervallen ablehnen, die durch Stichproben anstelle der Nullhypothese erstellt wurden?
- Sie sehen die Konfidenzintervalle möglicherweise als einen Wertebereich, für den ein Hypothesentest auf der Ebene $ \ alpha $ span> erfolgreich sein würde. und außerhalb des Bereichs ein Hypothesentest auf $ \ alpha $ span> -Niveau würde fehlschlagen.
Das heißt, wir wählen den Bereich von $ \ theta $ span> (als Funktion von $ X $ span >) basierend auf einer Wahrscheinlichkeit, die von den $ \ theta $ span> abhängig ist. Zum Beispiel
$$ I _ {\ alpha} (X) = \ lbrace \ theta: F_X (\ alpha / 2, \ theta) \ leq X \ leq F_X (1- \ alpha / 2, \ theta) \ rbrace $$ span>
der Bereich aller Hypothesen $ \ theta $ span>, für die sich die Beobachtung in einem zweiseitigen $ \ alpha \ befindet % $ span> Hypothesentest.
Diese Bedingung, die Hypothesen, ändert sich mit der Transformation nicht. Beispielsweise ist die Hypothese $ \ theta = 1 $ span> dieselbe wie die Hypothese $ \ log (\ theta) = 0 $ span>.
Grafische Intuition
Sie können eine 2D-Ansicht von Hypothesen auf der x-Achse und Beobachtungen auf der y-Achse betrachten (siehe auch Die grundlegende Logik zum Erstellen eines Konfidenzintervalls):
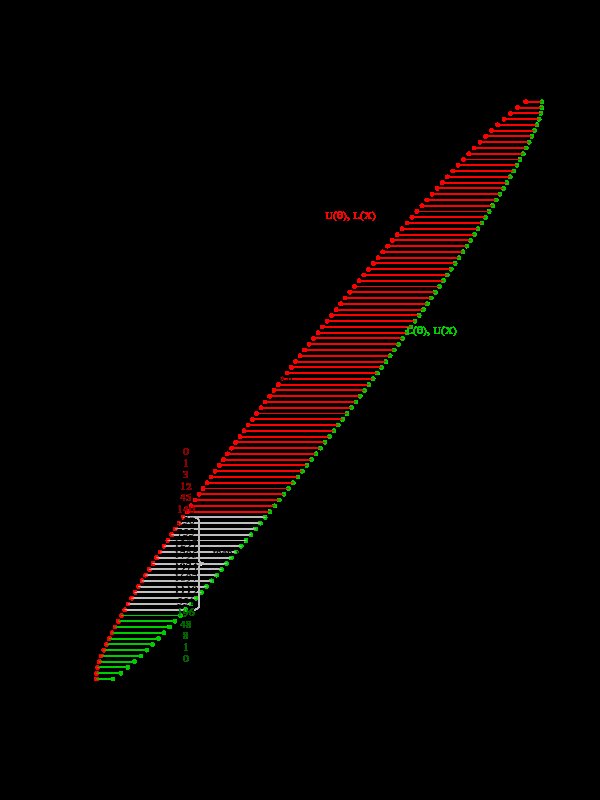
Sie können einen $ \ alpha $ span> -% -Konfidenzbereich auf zwei Arten definieren:
-
in vertikaler Richtung $ L (\ theta) < X < U (\ theta) $ span> die Wahrscheinlichkeit für die Daten $ X $ span>, vorausgesetzt, der Parameter ist wirklich $ \ theta $ span>, um innerhalb dieser Grenzen zu liegen, ist $ \ alpha $ span>.
in horizontaler Richtung $ L (X) < \ theta < U (X) $ span> die Wahrscheinlichkeit, dass ein Experiment den wahren Parameter innerhalb des Vertrauens hat Das Intervall ist $ \ alpha $ span>%.
Für die eigentliche Berechnung des Konfidenzintervalls verwenden wir die vertikale Richtung. Wir berechnen die Grenzen für jedes $ \ theta $ span> als Hypothesentest. Diese Berechnung ist dieselbe für einen transformierten $ \ theta $ span>.
Wenn Sie also den Parameter transformieren, sieht das Bild genauso aus und nur die Skalierung auf der x-Achse ändert sich. Für eine Transformation einer Wahrscheinlichkeitsdichte ist dies nicht dasselbe und die Transformation ist mehr als nur eine Änderung der Skala.
Allerdings
In der Tat, wie Ben geantwortet hat. Es gibt kein einziges Konfidenzintervall und es gibt viele Möglichkeiten, die Grenzen zu wählen. Wenn jedoch die Entscheidung getroffen wird, das auf Wahrscheinlichkeiten basierende Konfidenzintervall von den Parametern abhängig zu machen, spielt die Transformation keine Rolle (wie das zuvor erwähnte $ I _ {\ alpha} (X) = \ lbrace \ theta: F_X (\ alpha / 2, \ theta) \ leq X \ leq F_X (1- \ alpha / 2, \ theta) \ rbrace $ span>).
Ich würde nicht zustimmen, dass es ein kürzest mögliches Intervall gibt.
Oder zumindest kann dies nicht auf eindeutige Weise definiert werden, oder möglicherweise kann es basierend auf der bedingten Verteilung von Beobachtungen definiert werden, aber in diesem Fall spielt die Transformation (des bedingten Teils) keine Rolle.
In diesem Fall (basierend auf der bedingten Verteilung) definieren Sie die Grenzen so, dass die vertikale Richtung am kleinsten ist (z. B. wie Personen häufig die kleinsten Entscheidungsgrenzen für einen Hypothesentest treffen). Dies ist die häufigste Methode zur Bestimmung des Konfidenzintervalls. Die Optimierung des Konfidenzintervalls so, dass Sie das kleinste Intervall in vertikaler Richtung erhalten, ist unabhängig von Transformationen des Parameters (Sie können dies als Dehnen / Verformen der Figur in horizontaler Richtung betrachten, wodurch sich der Abstand zwischen den Grenzen in vertikaler Richtung nicht ändert). .
Es ist schwieriger, die Grenzen in horizontaler Richtung klein zu machen, da es keine gute Möglichkeit gibt, sie zu definieren / zu messen (um das Intervall für eine Beobachtung zu verkürzen, muss das Intervall für eine andere Beobachtung größer werden, und man muss auf irgendeine Weise wiegendie verschiedenen Beobachtungen).Es könnte möglicherweise möglich sein, wenn Sie einige vorherige für die Verteilung von $ \ theta $ span> verwenden.In diesem Fall könnte man die Auswahl der Grenzen verschieben (die immer noch in vertikaler Richtung liegen müssen, um eine Abdeckung von 95% zu gewährleisten, abhängig von $ \ theta $ span>, aber sie tun esmuss nicht in vertikaler Richtung optimal sein), um ein Maß für die Länge des Intervalls zu optimieren.In diesem Fall ändert die Transformation tatsächlich die Situation.Diese Art der Erstellung von Konfidenzintervallen ist jedoch nicht sehr typisch.